



工作量证明
在上一节,我们构造了一个非常简单的数据结构 -- 区块,它也是整个区块链数据库的核心。目前所完成的区块链原型,已经可以通过链式关系把区块相互关联起来:每个块都与前一个块相关联。
但是,当前实现的区块链有一个巨大的缺陷:向链中加入区块太容易,也太廉价了。而区块链和比特币的其中一个核心就是,要想加入新的区块,必须先完成一些非常困难的工作。在本文,我们将会弥补这个缺陷。
工作量证明
区块链的一个关键点就是,一个人必须经过一系列困难的工作,才能将数据放入到区块链中。正是由于这种困难的工作,才保证了区块链的安全和一致。此外,完成这个工作的人,也会获得相应奖励(这也就是通过挖矿获得币)。
这个机制与生活现象非常类似:一个人必须通过努力工作,才能够获得回报或者奖励,用以支撑他们的生活。在区块链中,是通过网络中的参与者(矿工)不断的工作来支撑起了整个网络。矿工不断地向区块链中加入新块,然后获得相应的奖励。在这种机制的作用下,新生成的区块能够被安全地加入到区块链中,它维护了整个区块链数据库的稳定性。值得注意的是,完成了这个工作的人必须要证明这一点,即他必须要证明他的确完成了这些工作。
整个 “努力工作并进行证明” 的机制,就叫做工作量证明(proof-of-work)。要想完成工作非常地不容易,因为这需要大量的计算能力:即便是高性能计算机,也无法在短时间内快速完成。另外,这个工作的困难度会随着时间不断增长,以保持每 10 分钟出 1 个新块的速度。在比特币中,这个工作就是找到一个块的哈希,同时这个哈希满足了一些必要条件。这个哈希,也就充当了证明的角色。因此,寻求证明(寻找有效哈希),就是矿工实际要做的事情。
哈希计算
在本节,我们会讨论哈希计算。如果你已经熟悉了这个概念,可以直接跳过。
获得指定数据的一个哈希值的过程,就叫做哈希计算。一个哈希,就是对所计算数据的一个唯一表示。对于一个哈希函数,输入任意大小的数据,它会输出一个固定大小的哈希值。下面是哈希的几个关键特性:
无法从一个哈希值恢复原始数据。也就是说,哈希并不是加密。
对于特定的数据,只能有一个哈希,并且这个哈希是唯一的。
即使是仅仅改变输入数据中的一个字节,也会导致输出一个完全不同的哈希。
哈希函数被广泛用于检测数据的一致性。软件提供者常常在除了提供软件包以外,还会发布校验和。当下载完一个文件以后,你可以用哈希函数对下载好的文件计算一个哈希,并与作者提供的哈希进行比较,以此来保证文件下载的完整性。
在区块链中,哈希被用于保证一个块的一致性。哈希算法的输入数据包含了前一个块的哈希,因此使得不太可能(或者,至少很困难)去修改链中的一个块:因为如果一个人想要修改前面一个块的哈希,那么他必须要重新计算这个块以及后面所有块的哈希。
Hashcash
比特币使用 Hashcash ,一个最初用来防止垃圾邮件的工作量证明算法。它可以被分解为以下步骤:
取一些公开的数据(比如,如果是 email 的话,它可以是接收者的邮件地址;在比特币中,它是区块头)
给这个公开数据添加一个计数器。计数器默认从 0 开始
将 data(数据) 和 counter(计数器) 组合到一起,获得一个哈希
检查哈希是否符合一定的条件:
如果符合条件,结束
如果不符合,增加计数器,重复步骤 3-4
因此,这是一个暴力算法:改变计数器,计算新的哈希,检查,增加计数器,计算哈希,检查,如此往复。这也是为什么说它的计算成本很高,因为这一步需要如此反复不断地计算和检查。
现在,让我们来仔细看一下一个哈希要满足的必要条件。在原始的 Hashcash 实现中,它的要求是 “一个哈希的前 20 位必须是 0”。在比特币中,这个要求会随着时间而不断变化。因为按照设计,必须保证每 10 分钟生成一个块,而不论计算能力会随着时间增长,或者是会有越来越多的矿工进入网络,所以需要动态调整这个必要条件。
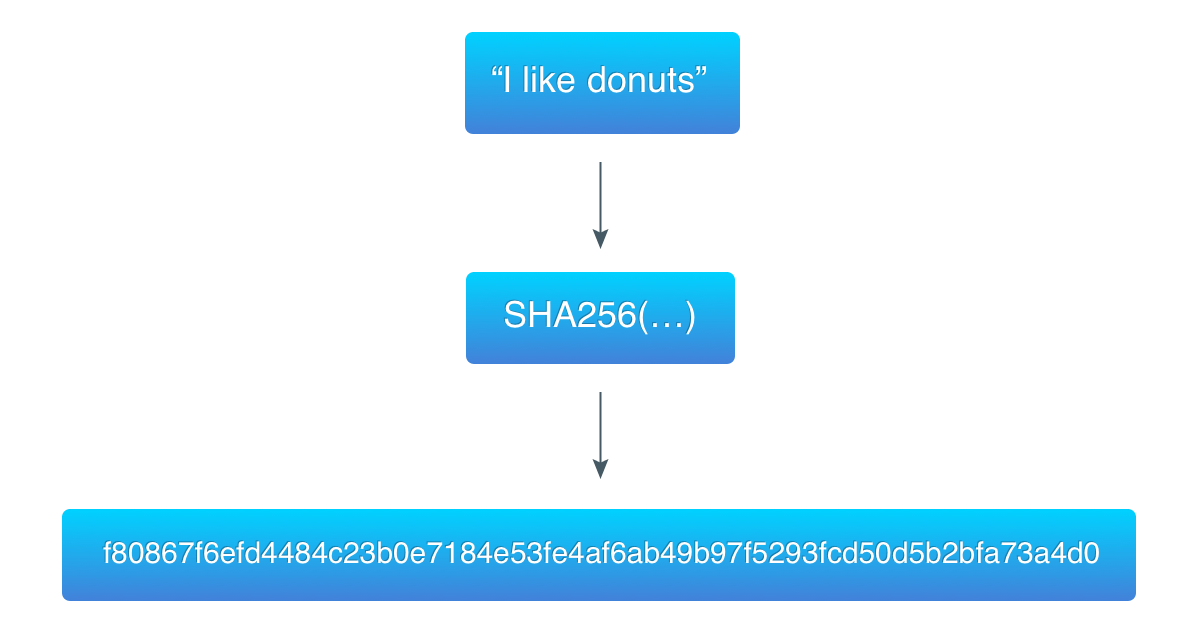
为了阐释这一算法,我从前一个例子(“I like donuts”)中取得数据,并且找到了一个前 3 个字节是全是 0 的哈希。
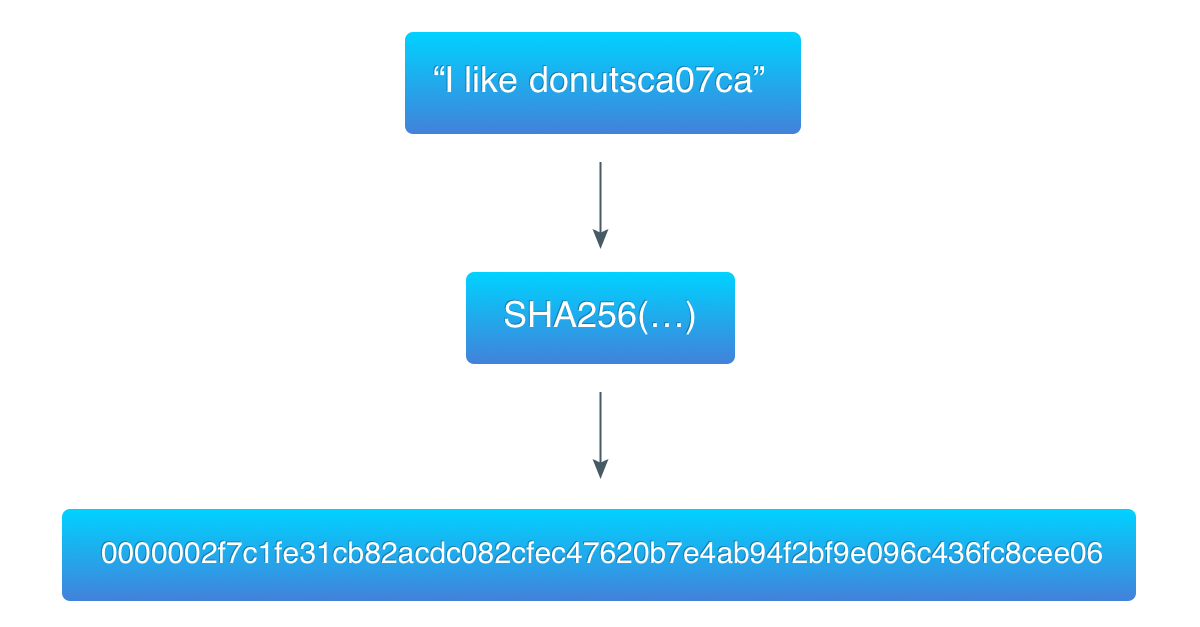
ca07ca 是计数器的 16 进制值,十进制的话是 13240266.
实现
好了,完成了理论层面,来动手写代码吧!首先,定义挖矿的难度值:
pub const TARGET_BITS: u16 = 24;
在比特币中,当一个块被挖出来以后,“target bits” 代表了区块头里存储的难度,也就是开头有多少个 0。这里的 24 指的是算出来的哈希前 24 位必须是 0,如果用 16 进制表示,就是前 6 位必须是 0,这一点从最后的输出可以看出来。目前我们并不会实现一个动态调整目标的算法,所以将难度定义为一个全局的常量即可。
24 其实是一个可以任意取的数字,其目的只是为了有一个目标(target)而已,这个目标占据不到 256 位的内存空间。同时,我们想要有足够的差异性,但是又不至于大的过分,因为差异性越大,就越难找到一个合适的哈希。
/// ProofOfWork is a struct that holds a block and a target
pub struct ProofOfWork {
/// block is a pointer to a block
pub block: Block,
/// target is a pointer to a target
pub target: BigUint,
}
impl ProofOfWork {
/// new is a constructor for ProofOfWork
pub fn new(b: Block) -> ProofOfWork {
let one: BigUint = One::one();
let target = one << (256u16 - TARGET_BITS);
ProofOfWork { block: b, target }
}
}
这里,我们构造了 ProofOfWork 结构,里面存储了指向一个块(block)和一个目标(target)的指针。这里的 “目标” ,也就是前一节中所描述的必要条件。这里使用了一个 大整数 ,我们会将哈希与目标进行比较:先把哈希转换成一个大整数,然后检测它是否小于目标。
在 ProofOfWork的New 函数中,我们将 BigUnit 初始化为 1,然后左移 256 - targetBits 位。256 是一个 SHA-256 哈希的位数,我们将要使用的是 SHA-256 哈希算法。target(目标) 的 16 进制形式为:
0x10000000000000000000000000000000000000000000000000000000000
它在内存上占据了 29 个字节。下面是与前面例子哈希的形式化比较:
0fac49161af82ed938add1d8725835cc123a1a87b1b196488360e58d4bfb51e3
0000010000000000000000000000000000000000000000000000000000000000
0000008b0f41ec78bab747864db66bcb9fb89920ee75f43fdaaeb5544f7f76ca
第一个哈希(基于 “I like donuts” 计算)比目标要大,因此它并不是一个有效的工作量证明。第二个哈希(基于 “I like donutsca07ca” 计算)比目标要小,所以是一个有效的证明。
译者注:上面的形式化比较有些“言不符实”,其实它应该并非由 “I like donuts” 而来,但是原文表达的意思是没问题的,可能是疏忽而已。下面是我做的一个小实验:
let data1 = b"I like donuts";
let data2 = b"I like donutsca07ca";
let one: BigUint = One::one();
let target = one << (256u16 - TARGET_BITS);
let data1_hash = calca_hash(data1);
let data2_hash = calca_hash(data2);
println!("{}", hex::encode(data1_hash));
println!("{:64x}", target);
println!("{}", hex::encode(data2_hash));
输出:
f80867f6efd4484c23b0e7184e53fe4af6ab49b97f5293fcd50d5b2bfa73a4d0
10000000000000000000000000000000000000000000000000000000000
0000002f7c1fe31cb82acdc082cfec47620b7e4ab94f2bf9e096c436fc8cee06
你可以把目标想象为一个范围的上界:如果一个数(由哈希转换而来)比上界要小,那么是有效的,反之无效。因为要求比上界要小,所以会导致有效数字并不会很多。因此,也就需要通过一些困难的工作(一系列反复地计算),才能找到一个有效的数字。
现在,我们需要有数据来进行哈希,准备数据:
/// prepare_data is a method that returns a byte array
pub fn prepar_data(&self, nonce: i64) -> Vec<u8> {
let mut data = vec![];
data.extend_from_slice(&self.block.prev_block_hash);
data.extend_from_slice(&self.block.data);
data.extend_from_slice(&self.block.timestamp.to_be_bytes());
data.extend_from_slice(&TARGET_BITS.to_be_bytes());
data.extend_from_slice(&nonce.to_be_bytes());
data
}
这个部分比较直观:只需要将 target ,nonce 与 Block 进行合并。这里的 nonce,就是上面 Hashcash 所提到的计数器,它是一个密码学术语。
很好,到这里,所有的准备工作就完成了,下面来实现 PoW 算法的核心:
pub fn run(&self) -> (i64, [u8; 32]) {
let mut hash = [0u8; 32];
let mut nonce = 0i64;
println!(
"Mining the block containing \"{}\"",
String::from_utf8_lossy(&self.block.data)
);
while nonce < i64::max_value() {
let data = self.prepar_data(nonce);
hash = calca_hash(&data);
let hash_int = BigUint::from_bytes_be(&hash);
if hash_int < self.target {
println!("\r{}", hex::encode(data));
break;
} else {
nonce += 1;
}
}
(nonce, hash)
}
首先我们对变量进行初始化:
HashInt是hash的整形表示;nonce是计数器。
然后开始一个 “无限” 循环:maxNonce 对这个循环进行了限制, 它等于 math.MaxInt64,这是为了避免 nonce 可能出现的溢出。尽管我们 PoW 的难度很小,以至于计数器其实不太可能会溢出,但最好还是以防万一检查一下。
在这个循环中,我们做的事情有:
准备数据
用 SHA-256 对数据进行哈希
将哈希转换成一个大整数
将这个大整数与目标进行比较
跟之前所讲的一样简单。现在我们可以移除 Block 的 SetHash 方法,然后修改 NewBlock 函数:
impl Block {
/// 创建新块时,需要把上一个块的哈希作为参数传进来
pub fn new(data: Vec<u8>, prev_block_hash: Hash) -> Self {
let now = OffsetDateTime::now_utc();
let timestamp = now.unix_timestamp();
let mut block = Block {
timestamp,
data,
prev_block_hash,
hash: [0; 32],
nonce: 0,
};
let pow = ProofOfWork::new(block.clone());
let (nonce, hash) = pow.run();
block.hash = hash;
block.nonce = nonce;
block
}
}
在这里,你可以看到 nonce 被保存为 Block 的一个属性。这是十分有必要的,因为待会儿我们对这个工作量进行验证时会用到 nonce 。Block 结构现在看起来像是这样:
#[derive(Debug, Clone)]
/// demo Bitcoin block
pub struct Block {
/// 当前时间戳,也就是区块创建的时间
pub timestamp: i64,
/// 区块存储的实际有效信息,也就是交易
pub data: Vec<u8>,
/// 前一个块的哈希,即父哈希
pub prev_block_hash: Hash,
/// 当前块的哈希
pub hash: Hash,
/// nonce
pub nonce: i64,
}
好了!现在让我们来运行一下是否正常工作:
Mining the block containing "Genesis Block"
00000041662c5fc2883535dc19ba8a33ac993b535da9899e593ff98e1eda56a1
Mining the block containing "Send 1 BTC to Ivan"
00000077a856e697c69833d9effb6bdad54c730a98d674f73c0b30020cc82804
Mining the block containing "Send 2 more BTC to Ivan"
000000b33185e927c9a989cc7d5aaaed739c56dad9fd9361dea558b9bfaf5fbe
Prev. hash:
Data: Genesis Block
Hash: 00000041662c5fc2883535dc19ba8a33ac993b535da9899e593ff98e1eda56a1
Prev. hash: 00000041662c5fc2883535dc19ba8a33ac993b535da9899e593ff98e1eda56a1
Data: Send 1 BTC to Ivan
Hash: 00000077a856e697c69833d9effb6bdad54c730a98d674f73c0b30020cc82804
Prev. hash: 00000077a856e697c69833d9effb6bdad54c730a98d674f73c0b30020cc82804
Data: Send 2 more BTC to Ivan
Hash: 000000b33185e927c9a989cc7d5aaaed739c56dad9fd9361dea558b9bfaf5fbe
成功了!你可以看到每个哈希都是 3 个字节的 0 开始,并且获得这些哈希需要花费一些时间。
还剩下一件事情需要做,对工作量证明进行验证:
pub fn validate(&self) -> bool {
let data = self.prepar_data(self.block.nonce);
let hash = calca_hash(&data);
let hash_int = BigUint::from_bytes_be(&hash);
hash_int.cmp(&self.target).is_lt()
}
这里,就是我们就用到了上面保存的 nonce。
再来检测一次是否正常工作:
impl Display for Block {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
let timestamp =
OffsetDateTime::from_unix_timestamp(self.timestamp).expect("convert timestamp error");
let pow = ProofOfWork::new(self.clone());
writeln!(f, "Time: {}", timestamp)?;
writeln!(f, "Prev. hash: {}", hex::encode(self.prev_block_hash))?;
writeln!(f, "Data: {}", String::from_utf8_lossy(&self.data))?;
writeln!(f, "Hash: {}", hex::encode(self.hash))?;
writeln!(f, "PoW: {}", pow.validate())
}
}
输出:
Mining the block containing "Genesis Block"
000000000000000000000000000000000000000000000000000000000000000047656e6573697320426c6f636b000000006566fcc4001800000000003aeab4
Mining the block containing "Send 1 BTC to Ivan"
0000000e8f938c1432e2c83f883a3d90fd660ea452a4891e16e7ef51823d89fe53656e6420312042544320746f204976616e000000006566fcef001800000000009cb328
Mining the block containing "Send 2 more BTC to Ivan"
00000032b4ecb716e213ec88fcff78098679c39c99a113c3d4dcd4d1e4e096df53656e642032206d6f72652042544320746f204976616e000000006566fd5d0018000000000062f8a9
Time: 2023-11-29 8:56:36.0 +00:00:00
Prev. hash: 0000000000000000000000000000000000000000000000000000000000000000
Data: Genesis Block
Hash: 0000000e8f938c1432e2c83f883a3d90fd660ea452a4891e16e7ef51823d89fe
PoW: true
Time: 2023-11-29 8:57:19.0 +00:00:00
Prev. hash: 0000000e8f938c1432e2c83f883a3d90fd660ea452a4891e16e7ef51823d89fe
Data: Send 1 BTC to Ivan
Hash: 00000032b4ecb716e213ec88fcff78098679c39c99a113c3d4dcd4d1e4e096df
PoW: true
Time: 2023-11-29 8:59:09.0 +00:00:00
Prev. hash: 00000032b4ecb716e213ec88fcff78098679c39c99a113c3d4dcd4d1e4e096df
Data: Send 2 more BTC to Ivan
Hash: 000000715b42a3f5278f449f32a6446b2671d9ff321db2d3c2f63dff75b0493e
PoW: true
从下图可以看出,这次我们产生三个块花费了一分多钟,比没有工作量证明之前慢了很多(也就是成本高了很多):
Mining the block containing "Genesis Block"
000000000000000000000000000000000000000000000000000000000000000047656e6573697320426c6f636b000000006566fcc4001800000000003aeab4
Mining the block containing "Send 1 BTC to Ivan"
0000000e8f938c1432e2c83f883a3d90fd660ea452a4891e16e7ef51823d89fe53656e6420312042544320746f204976616e000000006566fcef001800000000009cb328
Mining the block containing "Send 2 more BTC to Ivan"
00000032b4ecb716e213ec88fcff78098679c39c99a113c3d4dcd4d1e4e096df53656e642032206d6f72652042544320746f204976616e000000006566fd5d0018000000000062f8a9
Time: 2023-11-29 8:56:36.0 +00:00:00
Prev. hash: 0000000000000000000000000000000000000000000000000000000000000000
Data: Genesis Block
Hash: 0000000e8f938c1432e2c83f883a3d90fd660ea452a4891e16e7ef51823d89fe
PoW: true
Time: 2023-11-29 8:57:19.0 +00:00:00
Prev. hash: 0000000e8f938c1432e2c83f883a3d90fd660ea452a4891e16e7ef51823d89fe
Data: Send 1 BTC to Ivan
Hash: 00000032b4ecb716e213ec88fcff78098679c39c99a113c3d4dcd4d1e4e096df
PoW: true
Time: 2023-11-29 8:59:09.0 +00:00:00
Prev. hash: 00000032b4ecb716e213ec88fcff78098679c39c99a113c3d4dcd4d1e4e096df
Data: Send 2 more BTC to Ivan
Hash: 000000715b42a3f5278f449f32a6446b2671d9ff321db2d3c2f63dff75b0493e
PoW: true
总结
我们离真正的区块链又进了一步:现在需要经过一些困难的工作才能加入新的块,因此挖矿就有可能了。但是,它仍然缺少一些至关重要的特性:区块链数据库并不是持久化的,没有钱包,地址,交易,也没有共识机制。不过,所有的这些,我们都会在接下来的文章中实现,现在,愉快地挖矿吧!
参考: